安全工程专业课程
安全仿真与模拟基础
金洪伟 & 闫振国 & 王延平
西安科技大学安全科学与工程学院
如何浏览?
- 从浏览器地址栏打开 https://zimo.net/aqmn/;
- 点击章节列表中的任一链接,打开相应的演示文稿;
- 点击链接打开演示文稿,使用空格键或方向键导航;
- 按f键进入全屏播放,再按Esc键退出全屏;
- 按Alt键同时点击鼠标左键进行局部缩放;
- 按Esc或o键进入幻灯片浏览视图。
请使用最新版本浏览器访问此演示文稿以获得更好体验。
第 4 章
安全工程基础问题
仿真与模拟实战
目 录
1. 常见安全工程计算问题示例
❶ 煤层瓦斯含量预估
在煤矿开采前的地质勘探阶段,只能打有限数量的钻孔来测定煤层的瓦斯含量。已知某矿某煤层具有如下瓦斯含量数据:
| 采样点 | 埋藏深度 x (m) | 瓦斯含量 y (m3/t) |
|---|---|---|
| x1 | 400 | 5.0 |
| x2 | 500 | 7.0 |
| x3 | 600 | 11.0 |
计划在 550m 深的煤层中开凿巷道,该如何预估这里的煤层瓦斯含量?
1. 常见安全工程计算问题示例
❷ 煤与瓦斯突出后瓦斯涌出量计算
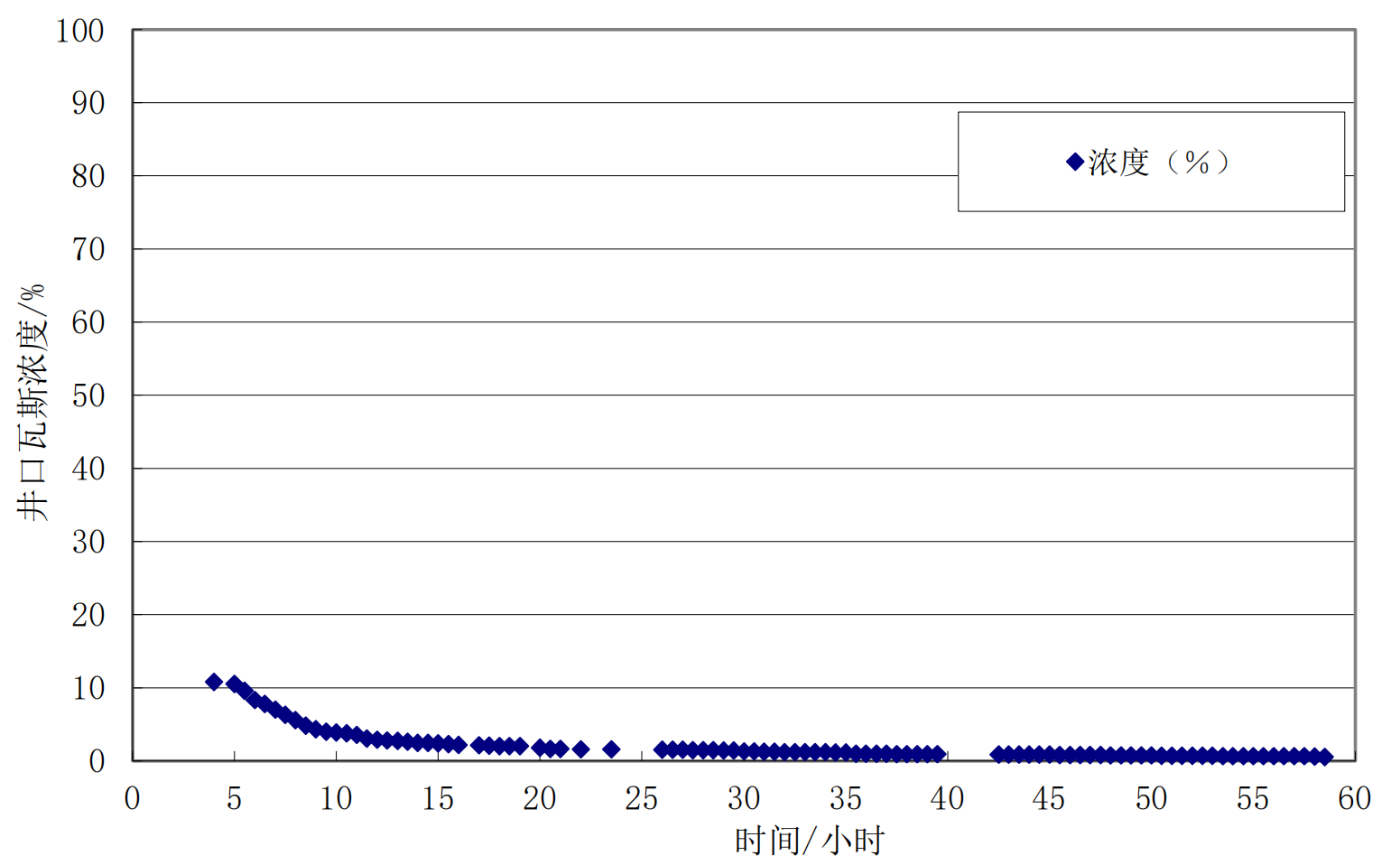
已知某煤矿井下发生一次煤与瓦斯突出事故,由于瓦斯监控系统损坏,在事故后前 4h 内未产生有效的瓦斯浓度监测数据,在 4h 后才由人工在地面回风井口进行瓦斯浓度检测,所得瓦斯浓度随时间变化的关系如右图所示。已知井筒风量是 1200m3/min。
该如何计算此次事故的瓦斯涌出总量?
1. 常见安全工程计算问题示例
❸ 煤炭自燃升温过程模拟
煤炭自燃是一个随时间推移温度累积的过程。氧化放热速率随温度升高而加快,呈指数关系;散热与环境温差成正比。已知描述温度随时间变化的微分方程是:
$$\frac{\mathrm{d}T}{\mathrm{d}t}=k_1e^{\alpha T}-k_2\left( T-T_{env} \right)$$
式中,\(\mathrm{d}T/\mathrm{d}t\) 为温度 T 对时间 t 的导数,即温度随时间的变化率;\(k_1\) 为产热系数/反应因子;\(k_2\) 为散热系数;\(\alpha\) 为反应速率对温度变化的敏感系数;\(T_{env}\) 为环境温度。
如果给定 \(k_1\), \(k_2\), \(\alpha\) 和 \(T_{env}\),并已知当前时刻的煤温 T,如何计算在反应开始一定时间(如 10d)后,煤体的温度?
1. 常见安全工程计算问题示例
❹ 矿井通风网络解算
已知煤矿通风网络方程及其定解条件可用如下矩阵方程组表征:
$$\begin{cases} \boldsymbol{MQ}^{\left( \mathrm{e} \right)}=0^{\left( \mathrm{v} \right)}\\ \mathrm{diag}\left( \boldsymbol{R}^{\left( \mathrm{e} \right)} \right) \mathrm{diag}\left( \left| \boldsymbol{Q}^{\left( \mathrm{e} \right)} \right| \right) \boldsymbol{Q}^{\left( \mathrm{e} \right)}-\boldsymbol{M}^{\mathrm{T}}\boldsymbol{P}_{t}^{\left( \mathrm{v} \right)}-\boldsymbol{H}_{N}^{\left( \mathrm{e} \right)}-\boldsymbol{H}_{f}^{\left( \mathrm{e} \right)}=0^{\left( \mathrm{e} \right)}\\ P_{t\,\,r}=P_0\\ \end{cases}$$
这是一个大型的非线性代数方程组。
已知各个巷道的风阻 \(R_i\),井口大气压 \(P_0\),已知巷道网络的关联矩阵 \(\boldsymbol{M}\),通风机的个体特性,该如何求解各巷道风量 \(Q_i\),以及各结点风压 \(P_j\)?
1. 常见安全工程计算问题示例
❺ 煤层瓦斯渗流解算
已知三维直角坐标系下的煤层瓦斯渗流控制方程为:
$$\frac{\partial}{\partial t}\left( \frac{\rho _cabp}{1+bp}+\frac{\varphi T_nZ_np}{TZp_n} \right) -\frac{\boldsymbol{K}T_nZ_n}{2\mu TZp_n}\left[ \frac{\partial ^2\left( p^2 \right)}{\partial x^2}+\frac{\partial ^2\left( p^2 \right)}{\partial y^2}+\frac{\partial ^2\left( p^2 \right)}{\partial z^2} \right] =0$$
这是一个椭圆型的非线性偏微分方程。
针对实际的煤层巷道,是否可以用此方程进行瓦斯涌出速率解算?如何进行?
解决问题不难,难的是“看清”问题。 很多时候,我们觉得工程问题无从下手,是因为我们还没把它“归类”到正确的数学抽屉里。
作为安全工程师,不仅要掌握各种仿真与模拟的计算工具,更要拥有对问题分类的透镜。所有的安全隐患,最终都只是某几类数学方程(科学本质)的伪装。解决这些问题的关键是理解它属于什么问题!
2. 回归分析问题示例
- 回归分析
- 在统计建模中,回归分析是一组统计过程,用于估计因变量(通常称为结果变量或响应变量,或机器学习术语中的标签)与一个或多个自变量(通常称为预测值、协变量、解释变量或特征)之间的关系。
- 在一个乱糟糟的散点图中,强行画出一条最靠谱的直线或曲线,让我们能根据一个变量算出另一个变量。
回归分析应用广泛,既可以建立输出模型、预测趋势,又可以用来探索影响因素,同时又是最基础、最常见的数据分析方法。
2. 回归分析问题示例
2.1 回归分析的基本步骤
-
看图说话(画散点图)
操作:拿到数据,先别急着算,先画散点图
目的:这是一个线性关系(直线)?还是非线性关系(弯曲的)?
-
选模具(选择拟合函数)
操作:在软件中选择“添加趋势线”
重点:不要乱选!要根据物理规律选。矿井通风阻力公式为 \(h=RQ^2\)。所以,必须强制选“二次多项式”,且截距设为 0(没有风就没有阻力)。如果选了线性回归,算出来的结果就是违背物理常识的。
2.1 回归分析的基本步骤
-
看效果(评估 R2)
操作:勾选“显示 R 平方值”
解释:R2 越接近 1,说明这条线画得越准,拟合效果越好。R2 很小(比如 0.3),说明这条线是瞎画的,不能用来做安全预测。
警示:哪怕 R2=0.99,也不代表绝对安全,要小心“过拟合”。
2.1 回归分析的基本步骤
显著性检验(选学)
在得出回归方程后,还需要检验回归方程对观测点的拟合程度好不好。可以使用统计学的检验理论检验回归模型的可靠性,具体又可以分为拟合优度检验、相关系数检验、模型的显著性检验(F-检验)和模型参数的显著性检验(t-检验)。
对于简单线性回归,F-检验、t-检验和相关系数检验的结果是完全一致的,而多元回归则不然。一般在简单线性回归时常使用相关系数检验,相关系数的平方 R2 的取值范围为 [0, 1],且其绝对值越接近 1,表明拟合程度越好。但应注意,当样本数量 n 越小时,相关系数 R2 越容易接近 1,这时并不能说 x 和 y 直接有密切的线性关系;另外,对相关系数的解释是依赖于具体的应用背景和目的的,假如你被告知地应力水平和发生煤与瓦斯突出灾害的之间的相关系数只有 0.3,也不能在预测突出时不考虑地应力水平指标。
2. 回归分析问题示例
2.2 用 Excel 实施简单问题回归
示例 1:根据角模压剪试验计算岩石强度性质
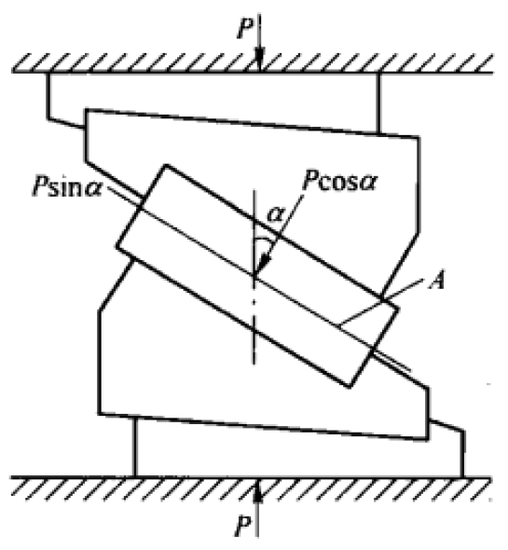
试件受力示意图
将某矿的页岩岩样做成 5cm×5cm×5cm 的三块立方体试件,分别做剪切角度为 45°、55° 和 65° 的抗剪强度试验,施加的最大载荷相应地为 22.4kN、15.3kN、12.3kN,求该页岩的黏聚力 C 和内摩擦角 φ 值,并绘出该页岩的抗剪强度曲线图。
示例 1:根据角模压剪试验计算岩石强度性质
分析:
根据《顶板管理与灾害防治》课程知识,已知可用莫尔—库伦公式表示岩石的强度:
$$\tau = \sigma \tan \varphi + c$$
式中,σ 为作用破坏面上的正应力;φ 为岩石的内摩擦角;c 为岩石的内聚力。
在本例中,\(\left( \sigma , \tau \right)\) 为通过测试得到的数据点,待求参数为 c 和 \(\varphi\)。根据上式,可知 \(\sigma\) 和 \(\tau\) 之间具有简单的线性关系。虽然能通过解方程组求得 c 和 \(\varphi\),但这样做,将难以充分利用所有测试数据。正确的方法是根据测试数据,进行线性回归分析。这样测试数据越多,与现实的逼近越好。
示例 1:根据角模压剪试验计算岩石强度性质
步骤 1:画散点图
需要把输入输入 Excel 表单中,计算出三个 \(\left( \sigma , \tau \right)\) 坐标对。
技巧与建议:
- 计算过程应采用国际标准单位制,以免发生单位转换错乱;
- Excel 的三角函数的输入参数都是弧度,可以使用
RADIANS()函数将角度转换为弧度; - 输入较大的数值时,可以采用科学计数法格式,如对 22.4kN,只用输入
22.4e3; - 对于涉及多行或多列的同类运算,只需要在开头输入运算公式,然后采用“拖曳”将这种计算应用到其他行或列。
步骤 1:画散点图
得到 \(\left( \sigma , \tau \right)\) 两列数据后,可以选择这两列输入,然后单击顶部的 插入 选项卡,选择插入 散点图,如下所示:
步骤 2:选择拟合函数
右键单击散点图上的数据点,在弹出的菜单中选择 添加趋势线(R)...
步骤 2:选择拟合函数
在右侧弹出的窗口中进行如下设置:
- 趋势线选项 中选择 线性;
- 选定 显示公式(E) 和 显示 R 平方值(R)
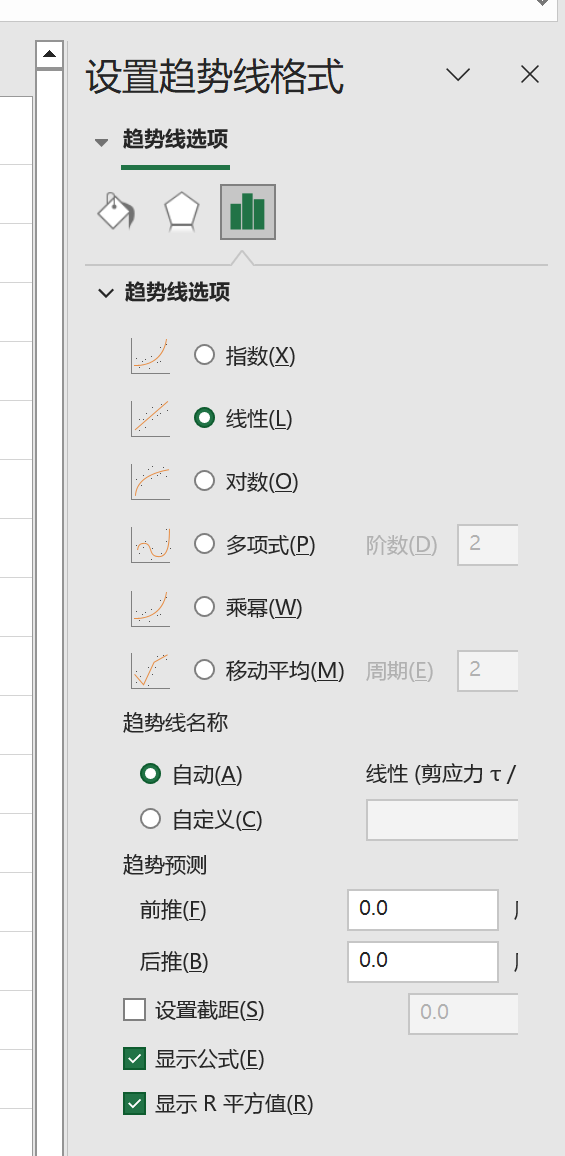
步骤 3:评估 R2
设置完成后,散点图中将显示趋势线、趋势线方程和 R2 值。可以进一步对该图进行格式设计与美化。
评估:R2=0.998,非常接近 1,因此判断拟合效果较好。
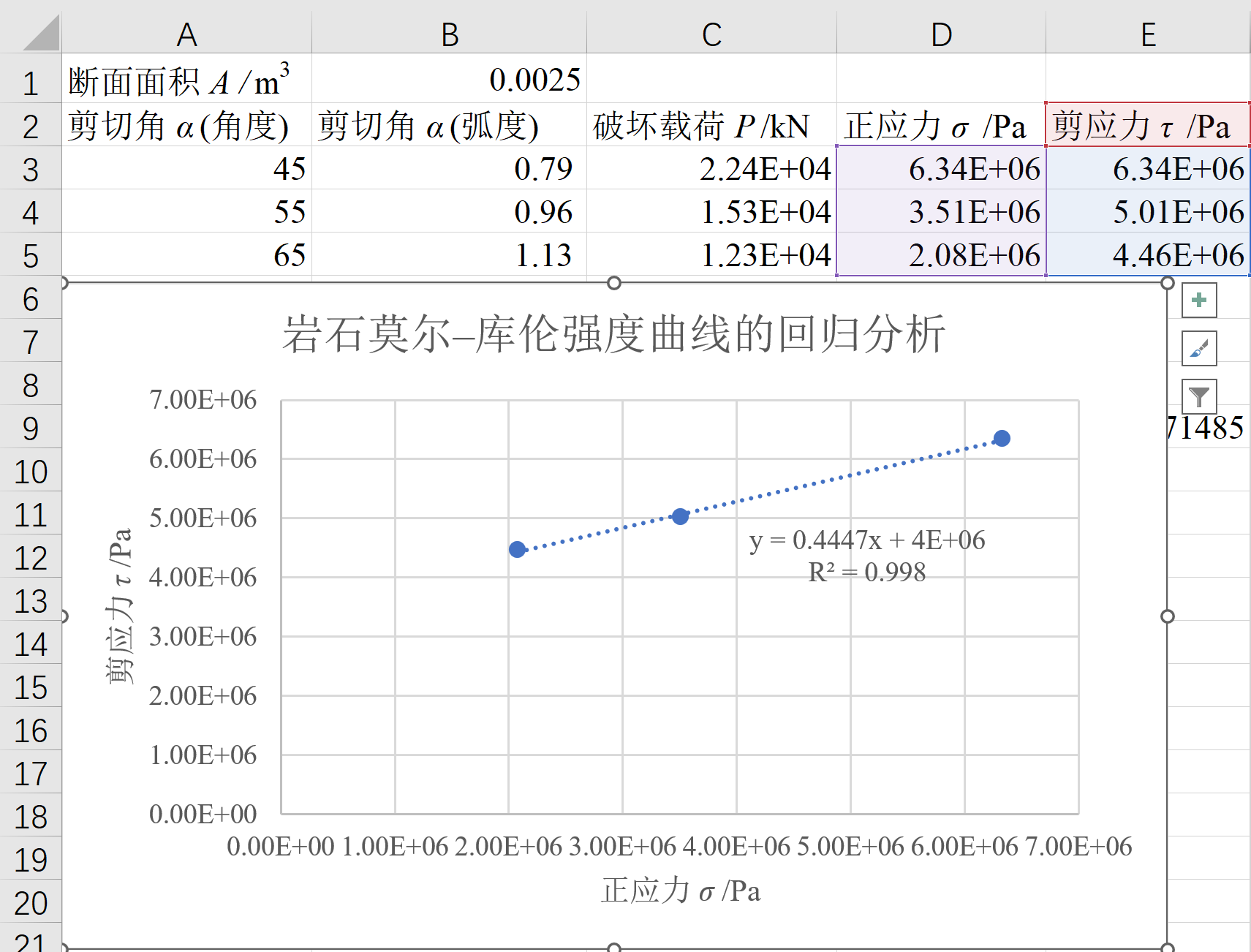
步骤 4:收尾工作
通过回归得到拟合公式:
$$\tau =0.4447\sigma +4.0\mathrm{E}6$$
因此可知,内聚力 c = 4.0E6Pa = 4.0MPa,\(\tan \varphi =0.4447\),需要进一步在 Excel 中计算内摩擦角 \(\varphi\) 的值。
提示:可使用 ATAN() 函数计算反正切,使用 DEGREES() 函数将弧度转换为角度。

2.2 用 Excel 实施简单问题回归
示例 2:根据筛分数据分析粒径分布特征
示例 1 相对非常简单,为了进一步揭示回归分析时可能使用到的一些技巧,这里将给出一个要复杂得多的示例。这里涉及的主要技巧是,将一个看似非线性的、复杂的回归模型,通过数据变换,变为简单线性回归。
问题描述:在煤矿煤与瓦斯突出时,经常会产生大量的各种粒径的碎煤,为了表征煤与瓦斯突出的剧烈程度,并研究其发生机理,需要通过对煤与瓦斯突出后产生的部分碎煤煤样进行筛分,得出这些碎煤的粒径分布规律。
下表为某次煤与瓦斯突出事故发生后,通过现场取样并筛分所得的数据,请进一步分析这些碎煤的粒径分布规律。
| 粒径范围 /mm |
筛孔尺寸 /mm |
碎煤质量 /g |
质量占比 /% |
累计质量比 (筛下率)/% |
累计质量比 (筛上率)/% |
|---|---|---|---|---|---|
| <3 | 3 | 347.0 | 7.669 | 7.669 | 92.331 |
| 3~6 | 6 | 171.5 | 3.790 | 11.459 | 88.541 |
| 6~9 | 9 | 123.3 | 2.725 | 14.183 | 85.817 |
| 9~12 | 12 | 151.6 | 3.350 | 17.534 | 82.466 |
| 12~15 | 15 | 144.3 | 3.189 | 20.723 | 79.277 |
| 15~18 | 18 | 242.1 | 5.350 | 26.073 | 73.927 |
| 18~21 | 21 | 277.4 | 6.130 | 32.203 | 67.797 |
| >21 | 3067.8 | 67.797 | 100.000 | 0.000 |
示例 2:根据筛分数据分析粒径分布特征
通过查阅文献资料得知,一般粉尘、碎煤的粒径都服从威布尔分布(或称韦伯分布)。因此,这里基于质量分布表示方法,首先尝试选用威布尔模型及其分布函数来分析煤与瓦斯突出后产生碎煤的分布特征。威布尔分布的累计概率积分函数为
$$F\left( d \right) =1-e^{-\left( d/d_e \right) ^k}$$
式中,d 为颗粒的粒径尺寸,mm;k 为形状参数,表征粒径分布范围大小,k 值越大,粒径分布越窄,它不仅影响粒径累积概率分布曲线的形状,还影响概率密度曲线的形状;de 尺度参数,de 越大,说明粒径从总体上会偏向较大的一端,反之,总体粒径较小,mm。
在该问题中,d 是自变量,F 是因变量,k 和 de 是未知参数。
示例 2:根据筛分数据分析粒径分布特征(选学)
以上累计概率积分函数虽然并非线性的,但可以通过一定的变换将其变为线性的。将上式进行移项并取两次对数,得
$$\ln \left[ -\ln \left( 1-F\left( d \right) \right) \right] =k\ln d-k\ln d_e$$
令 $x=\ln d$, $y=\ln \left[ -\ln \left( 1-F\left( d \right) \right) \right]$,代入上式得
$$y=kx-k\ln d_e$$
这是一个线性方程,可根据筛分数据用最小二乘法回归得出其参数,进而求得 k 和 de。
示例 2:根据筛分数据分析粒径分布特征
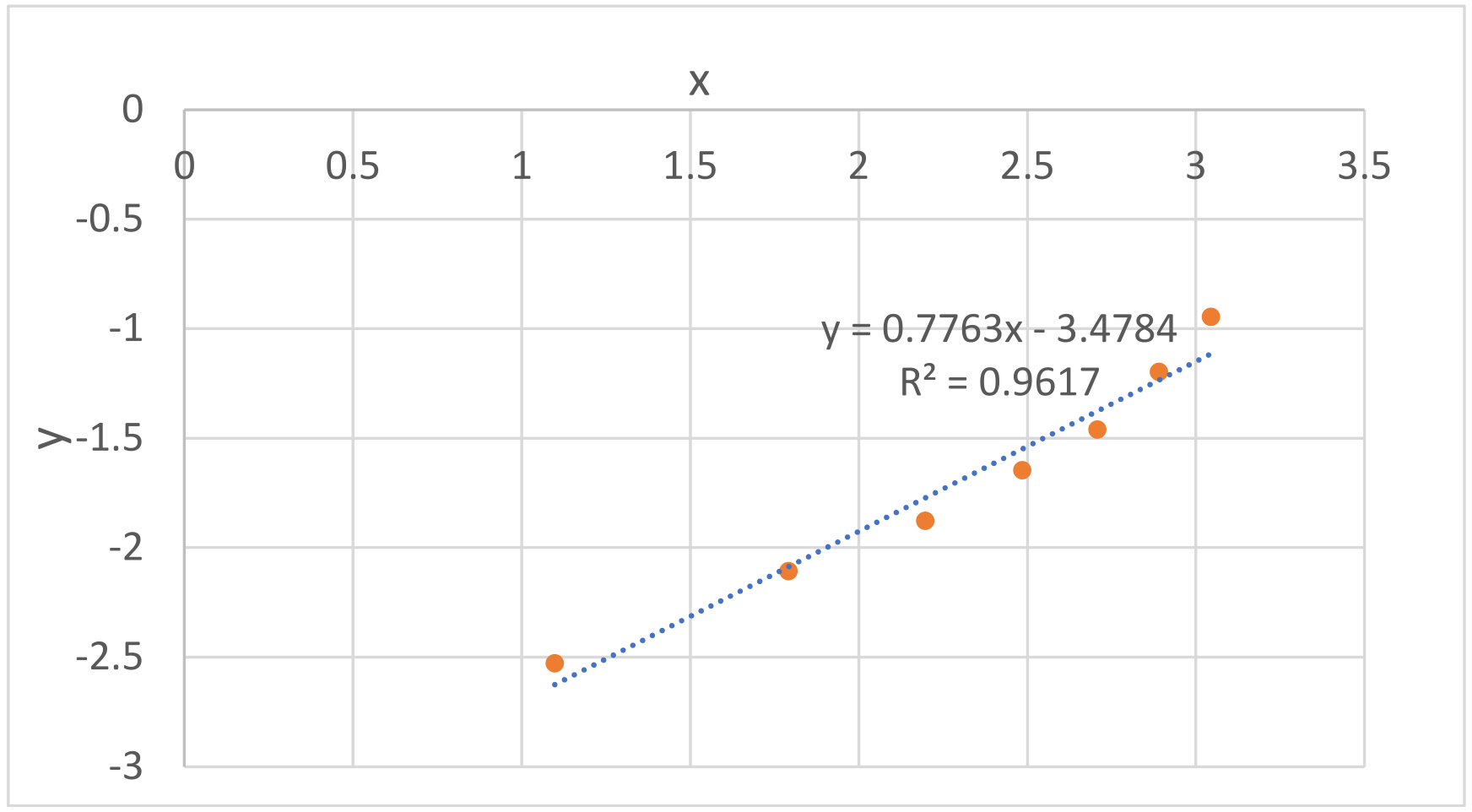
右图所示为根据前面表中实验筛分数据回归得到的曲线及方程。所得线性回归方程为 y = 0.7763x – 3.4784,其相关系数的平方R2 = 0.9617,非常接近 1。这说明碎煤粒径分布能很好地符合威布尔分布。将所得回归方程的参数代入上页最后一式,可进一步解得
k = 0.7763,de = 88.30
示例 2:根据筛分数据分析粒径分布特征
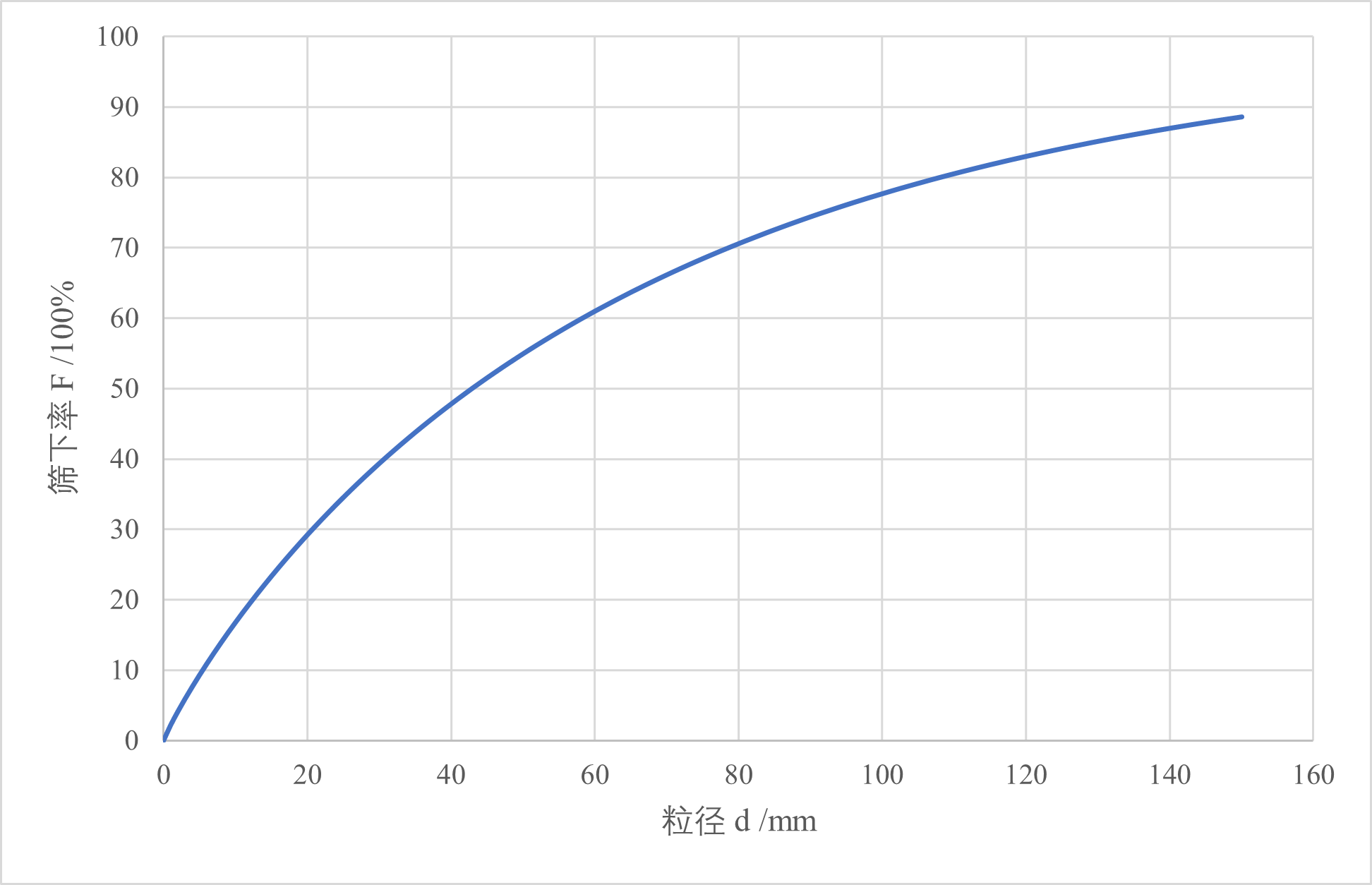
根据累计概率积分函数得出不同粒径对应的筛下率如下图所示:
2. 回归分析问题示例
2.3 用 Python 实施复杂问题回归
在 Excel 中,仅能对指数、线性、对数、多项式、乘幂、移动平均这些基础的函数进行回归分析,假如预期的拟合函数不属于这些类型,则 Excel 将无法胜任工作,以下将使用 Python 的 SciPy 模块进行复杂问题回归。
说明:对于示例 2,在用 Excel 回归时,需要先将其变为初等函数,然后再进行线性回归。这种方法看似可行,但实际对数变换会扭曲误差。线性化方法是计算机算力不足时代的产物(因为那时候手算线性回归很容易,手算非线性回归几乎不可能)。在现代科学计算中,直接针对原始方程进行非线性优化是标准做法。
2.3 用 Python 实施复杂问题回归
在 Python 中,scipy.optimize.curve_fit 是最常用的非线性最小二乘法拟合工具。它通过不断调整参数,使模型预测值与实际观测值之间的误差平方和最小。
from scipy.optimize import curve_fit
# 核心调用语句
popt, pcov = curve_fit(f=模型函数, xdata=x数据, ydata=y数据, p0=[猜想初值])f 是模型函数,可以随意定义,但函数的第一个参数必须是自变量;xdata, ydata 是真实数据数组;p0 是初始猜想,即给计算机一个查找的起点(对于复杂方程(如威布尔),不给初值可能导致拟合失败。
popt 里面包含函数 f 除了第一个自变量的参数值;pcov 是参数协方差矩阵(用于计算误差,初学可暂时忽略)。
示例 2:根据筛分数据分析粒径分布特征
代码列表:
import numpy as np
import matplotlib.pyplot as plt
from scipy.optimize import curve_fit
# 1. 准备数据
xdata = np.array([3.00, 6.00, 9.00, 12.00, 15.00, 18.00, 21.00])
ydata_percent = np.array([7.67, 11.46, 14.18, 17.53, 20.72, 26.07, 32.20])
# 将百分比转换为 0-1 的小数进行拟合,因为公式 F(d) 输出是概率(0-1)
ydata = ydata_percent / 100.0
# 2. 定义威布尔分布函数
def weibull_cdf(d, k, de):
return 1 - np.exp(-((d / de) ** k))
# 3. 进行非线性回归 (Curve Fitting)
# p0 是初始猜测值,这里假设 k=1, de=20
popt, pcov = curve_fit(weibull_cdf, xdata, ydata, p0=[1, 20])
k_fit = popt[0]
de_fit = popt[1]
print(f"拟合结果: k = {k_fit:.4f}, de = {de_fit:.4f}")
# 1. 生成用于画平滑曲线的 x 坐标 (从 0 到 25mm,生成 200 个点)
x_smooth = np.linspace(0, 25, 200)
# 2. 计算对应的 y 坐标 (用刚才算出来的 k_fit 和 de_fit)
# 记得乘回 100,为了图表上的单位是 %
y_smooth = weibull_cdf(x_smooth, k_fit, de_fit) * 100
# 3. 开始绘图
plt.figure(figsize=(8, 6))
plt.scatter(xdata, ydata_percent, color='red', label='实验数据') # 原始点
plt.plot(x_smooth, y_smooth, color='blue', label='威布尔拟合曲线') # 拟合线
plt.xlabel('粒径 d (mm)')
plt.ylabel('累积分布 F (%)')
plt.legend() # 显示图例
plt.grid(True) # 显示网格
plt.show()示例 2:根据筛分数据分析粒径分布特征
❶ 引入必要的核心库
import numpy as np
import matplotlib.pyplot as plt
from scipy.optimize import curve_fit❷ 数据录入与预处理
# 1. 准备数据
xdata = np.array([3.00, 6.00, 9.00, 12.00, 15.00, 18.00, 21.00])
ydata_percent = np.array([7.67, 11.46, 14.18, 17.53, 20.72, 26.07, 32.20])
# 将百分比转换为 0-1 的小数进行拟合
ydata = ydata_percent / 100.0❸ 定义数学模型
告诉计算机我们要拟合的“形状”是什么。这里就是把威布尔公式翻译成 Python 函数。函数定义的第一个参数必须是自变量 d,后面的参数是待求参数 (k, de)。
$$F\left( d \right) =1-e^{-\left( d/d_e \right) ^k}$$
# 2. 定义威布尔分布函数
def weibull_cdf(d, k, de):
"""
d: 粒径 (自变量)
k: 形状参数 (待求)
de: 尺度参数 (待求)
"""
return 1 - np.exp(-((d / de) ** k))❹ 进行拟合
这是最关键的一步,调用 curve_fit 让计算机自动寻找最佳参数。
# p0 是初始猜测值
# 这一步计算完成后,最佳参数会保存在 popt 中
popt, pcov = curve_fit(weibull_cdf, xdata, ydata, p0=[1, 20])
# 提取结果
k_fit = popt[0]
de_fit = popt[1]
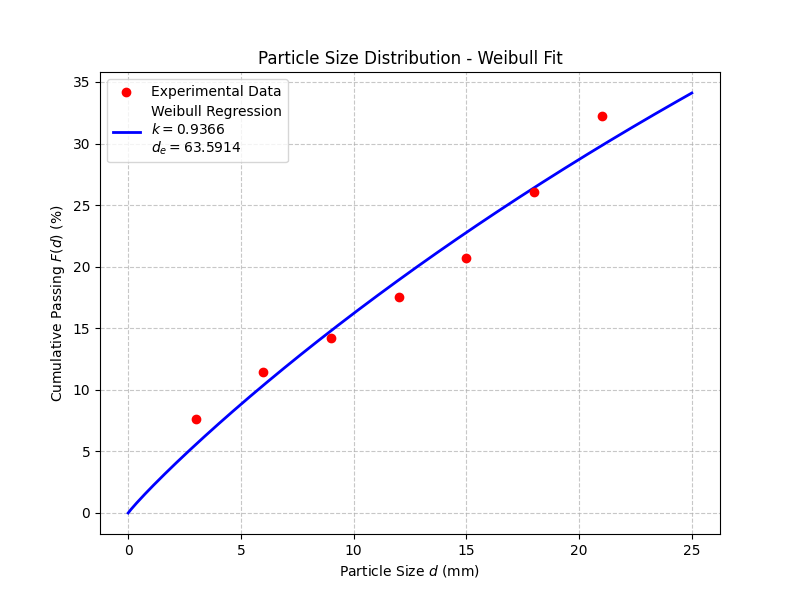
print(f"拟合结果: k = {k_fit:.4f}, de = {de_fit:.4f}")❺ 结果检验与绘图
用红点画原始实验数据,用蓝线画拟合出来的模型。画曲线不能只用原来的 7 个点,要生成一串密集的点(比如 200 个),这样曲线才平滑。
# 1. 生成用于画平滑曲线的 x 坐标 (从 0 到 25mm,生成 200 个点)
x_smooth = np.linspace(0, 25, 200)
# 2. 计算对应的 y 坐标 (用刚才算出来的 k_fit 和 de_fit)
# 记得乘回 100,为了图表上的单位是 %
y_smooth = weibull_cdf(x_smooth, k_fit, de_fit) * 100
# 3. 开始绘图
plt.figure(figsize=(8, 6))
plt.scatter(xdata, ydata_percent, color='red', label='实验数据') # 原始点
plt.plot(x_smooth, y_smooth, color='blue', label='威布尔拟合曲线') # 拟合线
plt.xlabel('粒径 d (mm)')
plt.ylabel('累积分布 F (%)')
plt.legend() # 显示图例
plt.grid(True) # 显示网格
plt.show()❺ 结果检验与绘图
3. 插值问题示例
- 插值
- 通过已知的、离散的数据点,在范围内推求新数据点的过程。
插值与拟合的区别:插值必须精确通过每一个已知数据点(认为观测数据是准确无误的,或必须被保留的);拟合 是寻找一条反映整体趋势的曲线,不要求通过每一个点,允许数据存在噪声或误差。
SciPy 中有几个通用工具可用于对 1 维、2 维和更高维的数据进行插值和平滑。具体插值程序的选择取决于数据:它是一维的,是在结构化网格上给出的,还是非结构化的。另一个因素是所需的平滑度。
可通过 scipy.interpolate 进行插值工具的选择。
3. 插值问题示例
示例 3:沿巷道煤层厚度变化插值
假设某条煤层平巷揭露了大约 900m 的煤层情况,约每 100m 记录一次煤厚。请通过这些有限的离散点,估算掘进 450.5m 时的煤层厚度,并绘制煤层厚度变化曲线。
dist_known = np.array([0, 110, 203, 280, 433, 498, 630, 713, 792, 910])
thickness_known = np.array([2.35, 2.42, 2.60, 2.85, 3.05, 3.10, 2.95, 2.70, 2.50, 2.30])分析:在煤矿地质中,煤厚通常是连续变化的(沉积环境决定的)。在一维插值时,为了使数据连续,一般使用三次样条曲线插值,它可以像一根弯曲的弹性钢条穿过所有点,保证了一阶和二阶导数连续。
示例 3:沿巷道煤层厚度变化插值
import numpy as np
import matplotlib.pyplot as plt
from scipy.interpolate import CubicSpline
# 1. 准备已知数据
dist_known = np.array([0, 110, 203, 280, 433, 498, 630, 713, 792, 910])
thickness_known = np.array([2.35, 2.42, 2.60, 2.85, 3.05, 3.10, 2.95, 2.70, 2.50, 2.30])
# 2. 创建插值对象
# 它是目前 SciPy 推荐的标准方法,专门用于生成平滑曲线
cs_model = CubicSpline(dist_known, thickness_known)
current_dist = 450.5
predicted_thickness = cs_model(current_dist)
print(f"掘进距离: {current_dist}m -> 预测厚度: {predicted_thickness:.4f}m")
# 它可以直接计算导数!(即煤厚的变化率)
# 1 表示求一阶导数
rate_of_change = cs_model(current_dist, 1)
print(f"在 {current_dist}m 处的变化率: {rate_of_change:.4f}m/m")
# 3. 绘图
x_smooth = np.linspace(0, 910, 500)
y_smooth = cs_model(x_smooth)
plt.figure(figsize=(10, 6))
# 画已知点
plt.scatter(dist_known, thickness_known, color='red', s=80, label='Measured Data', zorder=5)
# 画插值曲线
plt.plot(x_smooth, y_smooth, color='blue', linewidth=2.5, label='Cubic Spline Profile')
# 标记预测点
plt.scatter([current_dist], [predicted_thickness], color='green', marker='*', s=200, label=f'Prediction', zorder=10)
plt.title('Coal Seam Thickness (Method: CubicSpline)', fontsize=14)
plt.xlabel('Excavation Distance (m)', fontsize=12)
plt.ylabel('Seam Thickness (m)', fontsize=12)
plt.grid(True, linestyle='--', alpha=0.5)
plt.legend()
plt.ylim(2.0, 3.5)
plt.tight_layout()
plt.show()示例 3:沿巷道煤层厚度变化插值
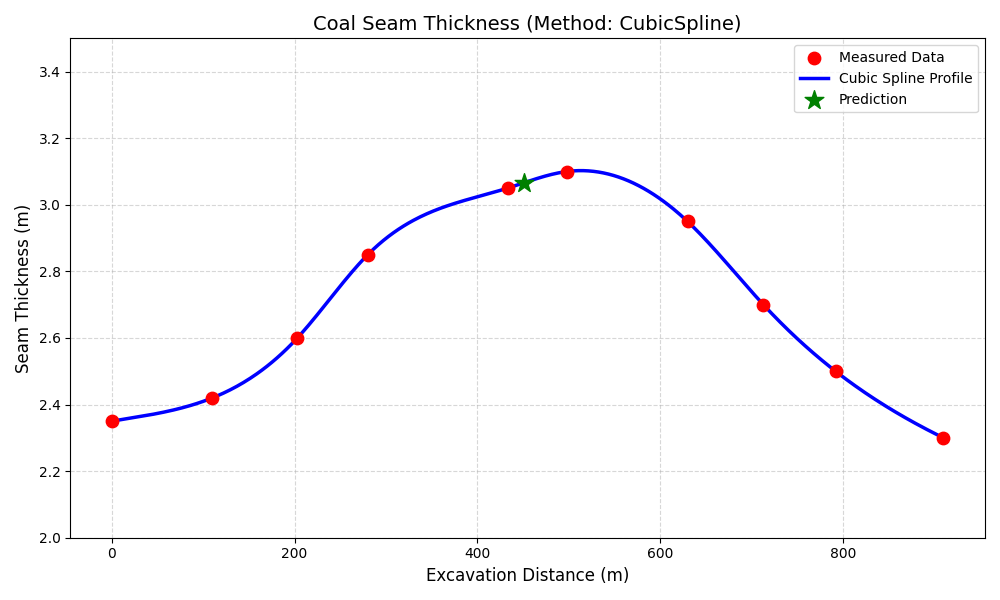
3. 插值问题示例
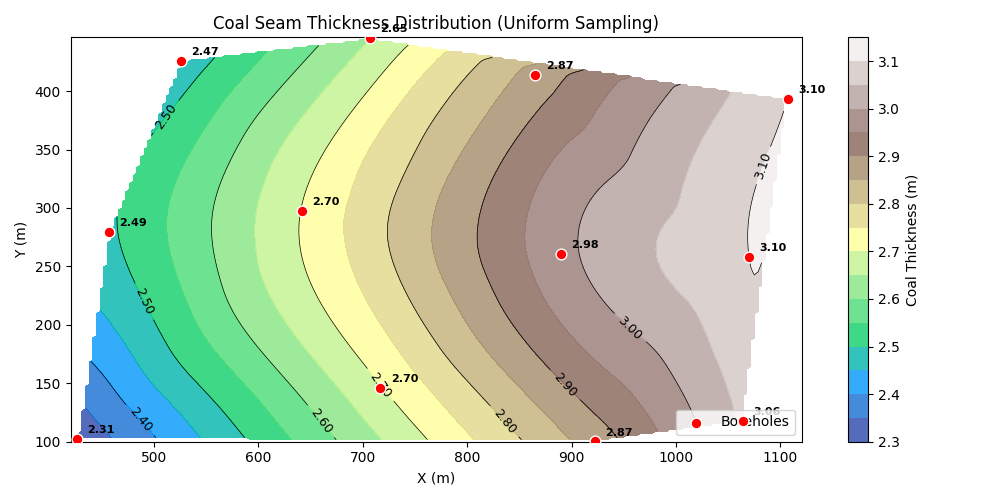
示例 4:采区内煤层厚度插值
已知某煤矿的一个采区内,共布置了 13 个勘探钻孔,揭露得到了不同坐标处煤层厚度数据。请根据这些数据,绘制该区域内的煤层等厚线图。
分析:这是一个非常典型的二维空间数据插值问题,也是煤矿地质绘图的核心技术。在这个场景中,我们需要完成从“散点数据”到“网格数据”的转换,才能绘制出等值线图。这里我们使用了 scipy.interpolate.griddata,它是处理此类地质数据最通用的工具。
示例 4:采区内煤层厚度插值
import numpy as np
import matplotlib.pyplot as plt
from scipy.interpolate import griddata
# ==========================================
# 1. 数据生成:网格抖动法 (Grid + Jitter)
# ==========================================
np.random.seed(2025) # 固定种子
# 采区边界
x_min, x_max = 420, 1121
y_min, y_max = 100, 446
# 设定网格行列数:4列 x 3行 = 12个点 (接近13个)
nx, ny = 4, 3
# 生成理想的网格坐标 (linspace)
x_grid = np.linspace(x_min + 50, x_max - 50, nx) # 内缩一点,避免点压在边界上
y_grid = np.linspace(y_min + 30, y_max - 30, ny)
# 创建网格矩阵
X_mesh, Y_mesh = np.meshgrid(x_grid, y_grid)
# 展平为一维数组
x_points = X_mesh.flatten()
y_points = Y_mesh.flatten()
# 【关键步骤】加入随机抖动 (Jitter)
# 让每个点在 X方向 ±60m, Y方向 ±30m 范围内随机移动
# 这样既保持了均匀的间距,又看起来像真实的随机分布
x_jitter = np.random.uniform(-60, 60, size=x_points.shape)
y_jitter = np.random.uniform(-30, 30, size=y_points.shape)
x_final = x_points + x_jitter
y_final = y_points + y_jitter
# 为了保证插值能填满矩形的四个角,我们手动把最外围的几个点“推”向边界
# 或者直接在四个角强制补点(为了教学简单,这里不做强制,目前的网格分布已经能撑开矩形了)
# 生成煤厚数据 (模拟地质规律)
def get_thickness(x, y):
# 归一化便于计算
xn = (x - x_min) / (x_max - x_min)
yn = (y - y_min) / (y_max - y_min)
# 趋势:沿X轴线性增加,沿Y轴有个小波浪
val = 2.3 + 0.8 * xn + 0.15 * np.sin(3 * yn)
return np.clip(val, 2.3, 3.1) # 限制在 2.3 - 3.1 之间
thickness_final = get_thickness(x_final, y_final)
# ==========================================
# 2. 定义插值函数 (封装为函数,方便调用)
# ==========================================
def interpolate_coal_seam(x_query, y_query):
"""
输入任意坐标 (x, y),返回插值后的煤厚。
使用 cubic (三次样条) 插值。
"""
# 注意:griddata 每次调用都会重新计算三角剖分,效率较低。
# 如果要频繁调用,建议用 LinearNDInterpolator 或 CloughTocher2DInterpolator
# 但对于教学演示,griddata 最简单直观。
z_query = griddata((x_final, y_final), thickness_final, (x_query, y_query), method='cubic')
return z_query
# ==========================================
# 3. 绘图:生成矩形等值线图
# ==========================================
# 生成绘图用的密集网格 (覆盖整个矩形区域)
plot_grid_x, plot_grid_y = np.mgrid[x_min:x_max:200j, y_min:y_max:200j]
# 计算网格上的煤厚
plot_grid_z = interpolate_coal_seam(plot_grid_x, plot_grid_y)
plt.figure(figsize=(10, 5)) # 调整画布比例,适应扁长地形
# 绘制等值线填充
contour = plt.contourf(plot_grid_x, plot_grid_y, plot_grid_z, levels=15, cmap='terrain', alpha=0.8)
plt.colorbar(contour, label='Coal Thickness (m)')
# 绘制等值线线条
line_contour = plt.contour(plot_grid_x, plot_grid_y, plot_grid_z, levels=8, colors='black', linewidths=0.5)
plt.clabel(line_contour, inline=True, fontsize=9, fmt='%.2f')
# 绘制钻孔位置
plt.scatter(x_final, y_final, c='red', s=60, edgecolors='white', zorder=10, label='Boreholes')
# 标注数值
for i in range(len(x_final)):
plt.text(x_final[i]+10, y_final[i]+5, f"{thickness_final[i]:.2f}", fontsize=8, color='black', fontweight='bold')
plt.title('Coal Seam Thickness Distribution (Uniform Sampling)', fontsize=12)
plt.xlabel('X (m)')
plt.ylabel('Y (m)')
plt.xlim(x_min, x_max)
plt.ylim(y_min, y_max)
plt.legend(loc='lower right')
plt.tight_layout()
plt.show()
# 打印生成的钻孔数据供检查
print("生成的均匀钻孔数据预览:")
for i in range(len(x_final)):
print(f"孔号{i+1}: X={x_final[i]:.1f}, Y={y_final[i]:.1f}, 厚度={thickness_final[i]:.2f}m")示例 4:采区内煤层厚度插值