安全工程专业课程
安全仿真与模拟基础
金洪伟 & 闫振国 & 王延平
西安科技大学安全科学与工程学院
如何浏览?
- 从浏览器地址栏打开 https://zimo.net/aqmn/;
- 点击章节列表中的任一链接,打开相应的演示文稿;
- 点击链接打开演示文稿,使用空格键或方向键导航;
- 按f键进入全屏播放,再按Esc键退出全屏;
- 按Alt键同时点击鼠标左键进行局部缩放;
- 按Esc或o键进入幻灯片浏览视图。
请使用最新版本浏览器访问此演示文稿以获得更好体验。
第 2 部分 Python 基础
第 4 章 数据结构
目 录
1. 概述
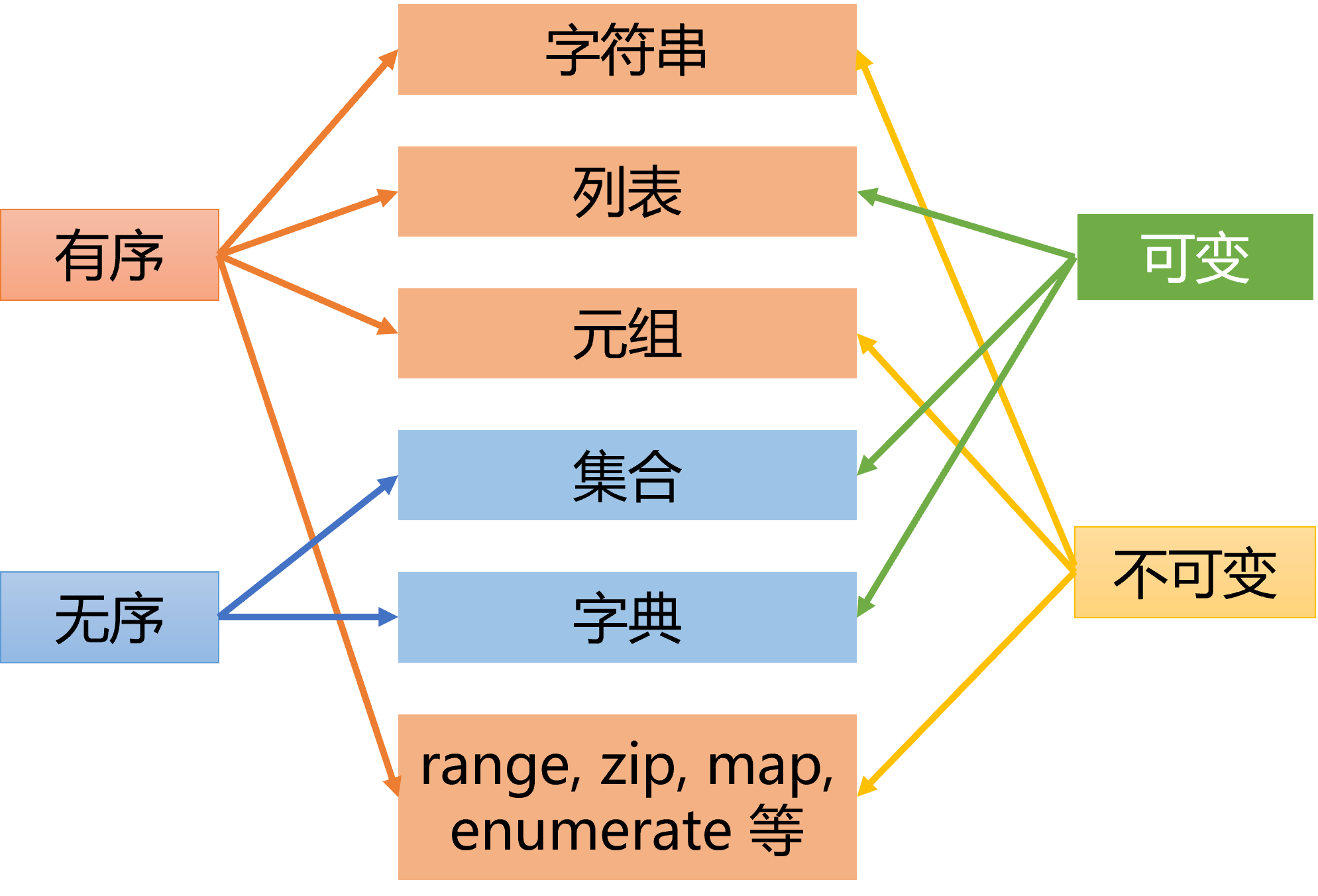
Python 中具有一些内建的数据结构,这些数据结构能方便地存储数据,并具有特殊的方法来获取或操纵数据。
常用的内建数据结构包括:
- 列表(List)是一种有序的集合,可以随时添加和删除其中的元素。
- 元组(Tuple)是另一种有序的集合,与列表相似,但一旦初始化就不能修改。
- 集合(Set)是一个无序的不含重复元素的集合。
- 字典(Dictionary)是一个无序的“键: 值”对的集合,其中每个键必须是唯一的。
这四种类型都相当于存储数据的容器,也可统称为容器(Container)类型或集合(Collection)类型。
1. 概述
在这些数据结构中,字符串、列表、元组以及 range、zip、map 和 enumerate 等这些有序类型又都属于序列类型。其中列表、元组、range 对象为三种基本的序列类型。
序列是一块用于存放多个值的连续内存空间,并且按一定顺序排列,每一个值(称为元素)都分配一个数字,称为索引或位置,通过该索引可以取出相应的值。
序列类型支持一些通用的操作,包括索引、切片、拼接(序列相加)、重复(序列与自身多次相加)、用 in 运算符检查某个元素是否是序列成员、通过内置函数计算序列的长度/最大值/最小值等。
集合和字典也支持一些序列操作,但严格来说,他们不属于序列类型,他们都不支持索引、切片、相加和相乘操作。
1. 概述
| 运算 | 结果 |
|---|---|
x in s |
如果 s 中的某项等于 x 则结果为 True,否则为 False |
x not in s |
如果 s 中的某项等于 x 则结果为 False,否则为 True |
s + t |
s 与 t 相拼接 |
s * n 或 n * s |
相当于 s 与自身进行 n 次拼接 |
s[i] |
s 的第 i 项,起始为 0 |
s[i:j] |
s 从 i 到 j 的切片 |
s[i:j:k] |
s 从 i 到 j 步长为 k 的切片 |
len(s) |
s 的长度 |
min(s) |
s 的最小项 |
max(s) |
s 的最大项 |
s.index(x[, i[, j]]) |
x 在 s 中首次出现项的索引号(索引号在 i 或其后且在 j 之前) |
s.count(x) |
x 在 s 中出现的总次数 |
1. 概述
| 运算 | 结果 |
|---|---|
s[i] = x |
将 s 的第 i 项替换为 x |
s[i:j] = t |
将 s 从 i 到 j 的切片替换为可迭代对象 t 的内容 |
del s[i:j] |
等同于 s[i:j] = [] |
s[i:j:k] = t |
将 s[i:j:k] 的元素替换为 t 的元素 |
del s[i:j:k] |
从列表中移除 s[i:j:k] 的元素 |
s.append(x) |
将 x 添加到序列的末尾 (等同于 s[len(s):len(s)] = [x]) |
s.clear() |
从 s 中移除所有项 (等同于 del s[:]) |
s.copy() |
创建 s 的浅拷贝 (等同于 s[:]) |
s.extend(t) 或 s += t |
用 t 的内容扩展 s (基本上等同于 s[len(s):len(s)] = t) |
s *= n |
使用 s 的内容重复 n 次来对其进行更新 |
s.insert(i, x) |
在由 i 给出的索引位置将 x 插入 s (等同于 s[i:i] = [x]) |
s.pop() 或 s.pop(i) |
提取在 i 位置上的项,并将其从 s 中移除 |
s.remove(x) |
删除 s 中第一个 s[i] 等于 x 的项目。 |
s.reverse() |
就地将列表中的元素逆序。 |
1. 概述
列表、元组、集合和字典都属于可迭代对象(即能通过 for 语句遍历的对象),Python 的标准库中内置了许多操作这些可迭代对象的函数,如下所示:
| 运算 | 结果 |
|---|---|
all(iterable) |
当 iterable 为空,或其中的所有元素都为真值返回 True |
any(iterable) |
当 iterable 中的任一元素为真值时返回 True |
sum(iterable, /, start=0) |
从 start 开始自左向右对 iterable 的项求和并返回总计值。 iterable 的项通常为数字,而 start 值则不允许为字符串。 |
str(object)
|
返回 object 的字符串表示形式 |
list(iterable)
|
根据 iterable 创建一个新的列表 |
tuple(iterable)
|
根据 iterable 创建一个新的元组 |
set(iterable)
|
根据 iterable 创建一个新的集合 |
dict(mapping)dict(iterable)
|
根据 mapping 或 iterable 创建一个新的字典 |
reversed(seq)
|
根据序列 seq 生成一个反向的迭代器 |
sorted(iterable)
|
根据 iterable 中的项返回一个新的已排序列表 |
enumerate(iterable, start=0)
|
返回一个枚举对象(由索引和值构成的元组形成的序列),一般用在 for 循环中 |
2. 列表
列表是任意对象的有序、可变序列,通常用于存放同类项目的集合。列表实现了前面给出的所有通用和可变序列的操作。
2.1 创建列表
可通过方括号来构建列表,方括号内的各个对象使用逗号 , 分割。如下所示:
pets = ['dog', 'cat', 'rabbit', 'fish']
squares = [1, 4, 9, 16, 25]
print(pets, type(pets)) # ['dog', 'cat', 'rabbit', 'fish'] <class 'list'>
print(squares, type(squares)) # [1, 4, 9, 16, 25] <class 'list'>
列表中也可以包含混合类型元素:
mixed_list = ['dog', 4, False, ['a', 'c']]
2.1 创建列表
不包含任何元素的列表称为空列表,用 [] 表示。下面创建一个名称为 empty_list 的空列表:
empty_list = []
也可以使用内置的 list() 函数(这是列表类型的构造器)从一个可迭代对象创建列表:
list1 = list( (1, 2, 3) ) # [1, 2, 3]
list2 = list( [1, 2, 3] ) # [1, 2, 3]
list3 = list('abcd') # ['a', 'b', 'c', 'd']
list4 = list(range(3, 13, 3)) # [3, 6, 9, 12]
list5 = list( {'mammal', 'bird', 'reptile', 'fish'} ) # ['mammal', 'fish', 'bird', 'reptile']
list6 = list() # 空列表 []
2.1 创建列表
还可以使用形如 [x for x in iterable] 的列表推导式创建列表:
list1 = [x for x in range(5)] # [0, 1, 2, 3, 4]
list2 = [x ** 2 for x in range(5)] # [0, 1, 4, 9, 16]
list3 = [x ** 2 for x in range(5) if x % 2 == 0] # [0, 4, 16]
上例中,list3 的创建相当于如下代码的简写形式:
list3 = []
for x in range(5):
if x % 2 == 0:
list3.append(x ** 2)
2.2 访问列表
可以使用与前面所述序列的通用操作访问列表元素,或对列表进行切分。如下所示:
pets = ['dog', 'cat', 'rabbit', 'fish']
print(pets[0]) # dog
print(pets[3]) # fish
print(pets[-1]) # fish
print(pets[-3]) # cat
print(pets[1:3]) # ['cat', 'rabbit']
print(pets[:3]) # ['dog', 'cat', 'rabbit']
print(pets[3:1:-1]) # ['fish', 'rabbit']
print(pets[:1:-1]) # ['fish', 'rabbit']
print(pets[:-3:-1]) # ['fish', 'rabbit']
print(pets[::-2]) # ['fish', 'cat']
2.3 追加、插入和删除列表元素
可以使用列表的 append() 方法将一个项目追加到列表的末尾,也可以使用 insert() 方法在特定的索引处插入项目,使用 pop() 方法移出(删除)列表中最后一个元素,使用 remove() 方法移除特定的元素值,使用 del 关键字删除特定索引对应的元素,甚至删除整个列表。
pets = ['dog', 'cat', 'rabbit', 'fish']
pets.append('chick') # 向列表的最后追加元素
print(pets) # ['dog', 'cat', 'rabbit', 'fish', 'chick']
pets.insert(0, 'snake') # 在索引 0 位置处插入 'snake',其他元素后移
print(pets) # ['snake', 'dog', 'cat', 'rabbit', 'fish', 'chick']
pets.pop() # 移出列表末尾的元素
print(pets) # ['snake', 'dog', 'cat', 'rabbit', 'fish']
pets.remove('rabbit') # 移除值为 'rabbit' 的元素,所要移除的值必须在列表中
print(pets) # ['snake', 'dog', 'cat', 'fish']
del pets[0] # 删除列表中索引为 0 的元素
print(pets) # ['dog', 'cat', 'fish']
del pets # 删除整个列表,pets 变量将不复存在
2.4 更改列表元素值
要更改某一元素值,需要通过索引访问列表中的元素,然后为其赋新值;也可以为列表的切片赋新值。如下所示:
pets = ['dog', 'cat', 'rabbit', 'fish']
pets[-1] = 'chick'
print(pets) # ['dog', 'cat', 'rabbit', 'chick']
pets[2:] = ['tortoise', 'snake', 'spider']
print(pets) # ['dog', 'cat', 'tortoise', 'snake', 'spider']
2.5 遍历列表
列表属于可遍历类型,可以使用 for 循环语句逐个访问列表元素:
pets = ['dog', 'cat', 'rabbit', 'fish']
for pet in pets:
print(pet)
# dog
# cat
# rabbit
# fish
2.6 对列表进行排序
在程序开发时,经常要对列表进行排序。Python 提供了两种常用的对列表进行排序的方法:使用列表的 sort() 方法,或使用内置的 sorted() 函数。
sort() 方法和 sorted() 函数的语法格式分别如下:
list_object.sort(key=None, reverse=False)
sorted(iterable, key=None, reverse=False)
其中 list_object 和 iterable 是要进行排序的对象。key 形参用于指定排序规则,默认为 None,表示直接按元素值进行排序;该参数的值为一个函数,此函数接受一个参数并返回一个用于排序的键,如设置为 key=str.lower 表示在排序时不区分字母大小写。reverse 形参为可选参数,默认为 False,表示按升序排序;如果设为 True,表示按降序排序。
2.6 对列表进行排序
sort() 方法使用示例:
pets = ['dog', 'cat', 'Rabbit', 'fish']
pets.sort()
print(pets) # ['Rabbit', 'cat', 'dog', 'fish']
pets = ['dog', 'cat', 'Rabbit', 'fish']
pets.sort(key=str.lower)
print(pets) # ['cat', 'dog', 'fish', 'Rabbit']
pets = ['dog', 'cat', 'Rabbit', 'fish']
pets.sort(key=str.lower, reverse=True)
print(pets) # ['Rabbit', 'fish', 'dog', 'cat']
2.6 对列表进行排序
sorted() 函数使用示例:
pets = ['dog', 'cat', 'Rabbit', 'fish']
pets_sorted = sorted(pets)
print(pets) # ['dog', 'cat', 'Rabbit', 'fish']
print(pets_sorted) # ['Rabbit', 'cat', 'dog', 'fish']
pets = ['dog', 'cat', 'Rabbit', 'fish']
pets_sorted = sorted(pets, key=str.lower, reverse=True)
print(pets_sorted) # ['Rabbit', 'fish', 'dog', 'cat']
关于排序的详细操作,请参见排序指南。
2.7 其他操作
可以使用 in 运算符检查某一元素是否存在:
pets = ['dog', 'cat', 'rabbit', 'fish']
print('cat' in pets) # True
count() 方法可获取指定元素出现的次数:
pets = ['dog', 'cat', 'rabbit', 'fish', 'cat']
print(pets.count('fish')) # 1
print(pets.count('cat')) # 2
2.7 其他操作
可以使用 extend() 方法将一个列表的所有元素添加到另外一个列表末尾:
nums1 = [1, 2, 3]
nums2 = [4, 5, 6]
nums1.extend(nums2)
print(nums1) # [1, 2, 3, 4, 5, 6]
可以使用 reverse() 方法将一个列表中的元素逆序:
nums1 = [1, 2, 3]
nums1.reverse()
print(nums1) # [3, 2, 1]
2.8 二维列表
当列表的元素也是列表时,相当于一个二维列表。如下代码创建了一个表示力学中应力张量(三维实对称二阶张量)的变量,并通过嵌套的 for 循环语句逐次访问并打印该张量的元素,最后计算该张量的对角元素之和(张量的第一不变量):
sigma = [[26.7, 25.6, 10.8],
[25.6, 30.1, 24.9],
[10.8, 24.9, 15.4]]
for row in sigma:
for element in row:
print(element, end='\t')
print()
i1 = sigma[0][0] + sigma[1][1] + sigma[2][2]
print(i1)
3. 元组
元组是任意对象的有序、不可变序列,通常用于储存异构数据的集合,或是同构数据的不可变序列。除了是不可变的,元组在其他方面和列表基本相同。元组实现了所有通用的序列操作。
3.1 创建元组
可通过圆括号来构建列表,圆括号内的各个对象使用逗号 , 分割。如下所示:
pets = ('dog', 'cat', 'rabbit', 'fish')
coordinate = (23.4, 35.6, 67.8)
mixed_tuple = ('dog', 4, False, ['a', 'c'])
print(pets, type(pets)) # ('dog', 'cat', 'rabbit', 'fish') <class 'tuple'>
print(coordinate, type(coordinate)) # (23.4, 35.6, 67.8) <class 'tuple'>
print(mixed_tuple, type(mixed_tuple)) # ('dog', 4, False, ['a', 'c']) <class 'tuple'>
3.1 创建元组
尽管在打印输出时,元组总由圆括号标注,但在输入时,圆括号是可有可无的。如下所示:
tuple1 = 1, 2, 3, 'c'
print(tuple1, type(tuple1)) # (1, 2, 3, 'c') <class 'tuple'>
请注意决定生成元组的其实是逗号而不是圆括号。圆括号只是可选的,生成空元组或需要避免语法歧义的情况除外。例如,f(a, b, c) 是在调用函数时传入三个参数,而 f((a, b, c)) 则是在调用函数时传输一个三元组参数。
3.1 创建元组
不包含任何元素的元组称为空元组,用 () 表示。下面创建一个名称为 empty_tuple 的空元组:
empty_tuple = ()
只包含一个元素的元组是单元组,其表示形式为:
singleton_tuple1 = 1,
singleton_tuple2 = (1,)
print(singleton_tuple1, type(singleton_tuple1)) # (1,) <class 'tuple'>
3.1 创建元组
也可以使用内置的 tuple() 函数(这是元组类型的构造器)从一个可迭代对象创建元组:
tuple1 = tuple( [1, 2, 3] ) # (1, 2, 3)
tuple2 = tuple( (1, 2, 3) ) # (1, 2, 3)
tuple3 = tuple('abcd') # ('a', 'b', 'c', 'd')
tuple4 = tuple(range(3, 13, 3)) # (3, 6, 9, 12)
tuple5 = tuple( {'mammal', 'bird', 'reptile', 'fish'} ) # ('reptile', 'bird', 'mammal', 'fish')
tuple6 = tuple() # 空元组 ()
3.2 打包和解包
形如 t = 33, 'hello', True 的语句称为元组打包,这将值 33, 'hello' 和 True 一起打包进元组。元组打包的逆操作为:
x, y, z = t
该操作被称为序列解包,其右侧可以是元组、列表、集合或字典这些容器类型。如下所示:
t = [33, 'hello', True] # 对列表解包
x, y, z = t
print(x, y, z) # 33 hello True
t = {33, 'hello', True} # 对集合解包
x, y, z = t
print(x, y, z) # 33 hello True
days = {1: 'Monday', 2: 'Tuesday', 3: 'Wednesday'} # 对字典解包
x, y, z = days
print(x, y, z) # 1 2 3
3.3 访问元组
读取、遍历元组的各种操作与列表类似,不再赘述。
3.4 元组与列表的区别
元组与列表很像,但两者使用场景不同,用途也不同。
元组是不可变的(immutable),一般可包含异质元素序列,常通过解包或索引访问。列表是可变的(mutable),列表元素一般为同质类型,常通过迭代访问。元组没有实现可变序列的操作,如添加或删除元素等。
元组比列表的访问和处理速度更快,所以当只是需要对其中的元素进行访问,而不进行任何修改时,建议使用元组。
列表不能作为字典的键,而元组可以。
4. 集合
集合是由不重复元素组成的无序容器。其基本用法包括成员检测、消除重复元素。集合对象支持并集、交集、差集、对称差集等数学运算。
4.1 创建集合
创建集合用花括号或 set() 函数。如下为使用花括号创建集合:
pets = {'dog', 'cat', 'rabbit', 'fish'}
lucky_number = {6, 8, 9}
mixed_set = {'dog', 4, False}
print(pets, type(pets)) # {'rabbit', 'fish', 'dog', 'cat'} <class 'set'>
print(lucky_number, type(lucky_number)) # {8, 9, 6} <class 'set'>
print(mixed_set, type(mixed_set)) # {False, 4, 'dog'} <class 'set'>
4.1 创建集合
使用 set() 函数创建集合:
set1 = set( [1, 2, 3] ) # {1, 2, 3}
set2 = set( (1, 2, 3) ) # {1, 2, 3}
set3 = set('abcd') # {'a', 'b', 'c', 'd'}
set4 = set(range(3, 13, 3)) # {9, 3, 12, 6}
set5 = set( {'mammal', 'bird', 'reptile', 'fish'} ) # {'mammal', 'bird', 'fish', 'reptile'}
set6 = set() # 空集合 set()
注意,空集合不能使用 {} 表示,而只能使用 set() 表示,前者表示一个空字典。
集合中的元素必须是可哈希的(hashable,要求其是不可变的),而列表是不可哈希的,因此 {'dog', 4, False, ['a', 'c']} 不是一个有效的集合字面量,但 {'dog', 4, False, ('a', 'c')} 是。
4.2 集合元素的添加和删除
集合是可变的,可以通过如下方式添加或删除集合中的元素:
pets = {'dog', 'cat', 'rabbit', 'fish'}
pets.add('snake') # add 方法用于向集合中添加元素
print(pets) # {'snake', 'rabbit', 'dog', 'cat', 'fish'}
pets.remove('rabbit') # remove 方法移除指定元素
print(pets) # {'fish', 'cat', 'dog', 'snake'}
pets.pop() # pop 方法随机从集合中删除一个元素
print(pets) # {'cat', 'fish', 'snake'}
pets.clear() # clear 方法删除集合中的所有元素
print(pets) # set()
del pets # del 删除集合
4.3 集合的并集、交集和差集运算
对 Python 中集合的运算与数学上集合的运算相似,如下所示:
- 并集:
A | B,得到两个集合的所有元素放在一起组成的新集合。 - 交集:
A & B,得到两个集合共有的元素放在一起组成的新集合。 - 差集,又称补集:
A - B,得到属于 A 的、但不属于 B 的元素组成的新集合。 - 对称差集:
A ^ B,得到属于 A 或 B,但不同时属于 A 和 B 的元素组成的新集合。
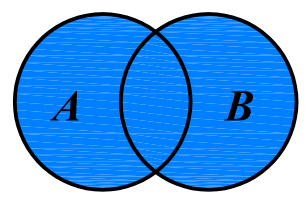
A | B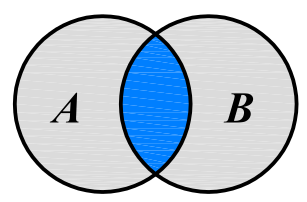
A & B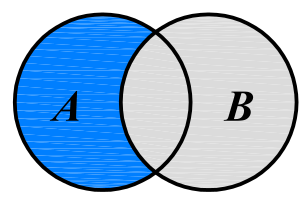
A - B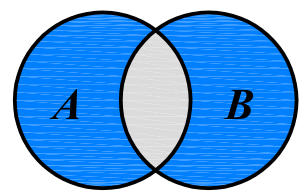
A ^ B4.3 集合的并集、交集和差集运算
A | B
A & B
A - B
A ^ B
a = {1, 2, 3, 4}
b = {3, 4, 5, 6}
print(a | b) # {1, 2, 3, 4, 5, 6}
print(a & b) # {3, 4}
print(a - b) # {1, 2}
print(a ^ b) # {1, 2, 5, 6}
5 字典
字典在其他语言中又常被称为关联数组、散列表或映射,它是一种无序的、可变的数据集合。字典中保存键: 值对(key:value pair)形式的数据。其中键必须是唯一的,且必须是可哈希(不可变)类型,通常为字符串或数字;而值可以为任意数据类型,且是可以重复的。字典的主要用途是通过键存储、提取值。
从 Python 3.7 开始,字典变为有序的,字典会保留插入时的顺序,对键的更新不会影响顺序,删除并再次添加的键将被插入到末尾。不过为了各个版本的兼容,目前尽量不要依赖字典中元素的排序来实现程序逻辑。
字典支持的常见操作见下页表。
| 运算 | 结果 |
|---|---|
list(d) |
返回字典 d 中使用的所有键的列表。 |
len(d) |
返回字典 d 中的项数。 |
d[key] |
返回字典 d 中以 key 为键的项,如果不存在此 key 则会引发 KeyError 错误。 |
d[key] = value |
将 d[key] 设为 value,如果存在 key,则修改其对应值,如果不存在,则添加项目。 |
del d[key] |
将 d[key] 从 d 中删除,如果不存在此 key 则会引发 KeyError 错误。 |
key in d |
如果在 d 中存在键 key 则返回 True,否则返回 False。 |
iter(d) |
返回以字典的键为元素的迭代器。这是 iter(d.keys()) 的快捷方式。 |
key not in d |
等价于 not key in d。 |
d.clear() |
移除字典中的所有元素。 |
d.copy() |
返回原字典的浅拷贝。 |
dict.fromkeys(iterable[, value]) |
使用来自 iterable 的键创建一个新字典,并将各个值设为 value。如果未提供 value,默认值为 None。 |
d.get(key[, default]) |
通过键获取值。如果 key 存在则返回对应值,否则返回 default,如果 default 未给出则默认为 None。相对于 d[key],该方法不会引发 KeyError 错误。 |
| 运算 | 结果 |
|---|---|
d.pop(key[, default]) |
通过键删除项。如果 key 存在于字典中则将其移除并返回其值,否则返回 default。 如果 default 未给出且 key 不存在,则会引发 KeyError 错误。 |
d.items() |
返回由字典中的元素(键/值对)组成的一个新视图。 |
d.keys() |
返回由字典中的键组成的一个新视图。 |
d.popitem() |
从字典中移除并返回一个键/值对。键/值对会按后进先出(LIFO)的顺序被返回。该方法适合对字典进行消耗性迭代。 |
reversed(d.keys()) |
返回一个逆序获取字典键的迭代器。 |
d.setdefault(key[, default]) |
如果字典存在键 key,返回它的值。如果不存在,插入值为 default 的键 key,并返回 default。default 默认为 None。该方法可以安全地向字典中插入值而不会覆盖已有值。 |
d.update([other]) |
使用字典 other 的键/值对更新字典,覆盖原有的键。返回 None。 |
d.values() |
返回由字典中的值组成的一个新视图。 |
d | other |
合并字典对象 d 和 other 中的键和值来创建一个新的字典。当 d 和 other 有相同键时,other 的值优先。 |
d |= other |
用 other 的键和值更新字典 d,other 可以是 mapping 或 iterable 的键/值对。当 d 和 other 有相同键时,other 的值优先。 |
5.1 字典的创建
可以在花括号内以逗号分隔的键: 值对表示字典:
pet = {'name': '多多', 'species': 'Dog', 'breed': 'Husky',
'age': 4, 'weight': 14.1}
days = {1: 'Monday', 2: 'Tuesday', 3: 'Wednesday',
4: 'Thursday', 5: 'Friday', 6: 'Saturday', 7: 'Sunday'}
students = {'20804070201': {'name': '张三', 'gender': '男'},
'20804070202': {'name': '李四', 'gender': '男'},
'20804070203': {'name': '王老五', 'gender': '男'},
'20804070204': {'name': '白冰冰', 'gender': '女'},
'20804070205': {'name': '赵晓静', 'gender': '女'}}
mixed_dict = {'name': '王老五', 34: 23.3, True: 'Something'}
empty_dict = {} # 空字典
5.1 字典的创建
也可以使用 dict() 函数(这是一个类型构造器)创建字典,该函数有多种形式:
a = {'one': 1, 'two': 2, 'three': 3} # 直接给出字典字面量
b = dict({'three': 3, 'one': 1, 'two': 2}) # 从字典创建字典
c = dict(one=1, two=2, three=3) # 通过给定关键字参数来创建字典
# 从包含键/值对元组的列表或元组创建字典
d = dict([('two', 2), ('one', 1), ('three', 3)])
# zip 函数在多个迭代器上并行迭代,从每个迭代器返回一个数据项组成元组。
# 该方法可以将多个列表或元组对应位置的元素组合为元组,进一步创建字典
e = dict(zip(['one', 'two', 'three'], [1, 2, 3])) # 拉链式键/值对
f = dict({'one': 1, 'three': 3}, two=2) # 混合使用各种方法
# 以上通过不同形式创建的字典是相等的:
print(a == b == c == d == e == f) # True
empty_dict = dict() # 空字典
5.1 字典的创建
还可以使用形如 {x: x for x in iterable} 的字典推导式创建字典:
dict1 = {x: x for x in range(5)} # {0: 0, 1: 1, 2: 2, 3: 3, 4: 4}
dict2 = {x: x ** 2 for x in range(5)} # {0: 0, 1: 1, 2: 4, 3: 9, 4: 16}
dict3 = {x: x ** 2 for x in range(5) if x % 2 == 0} # {0: 0, 2: 4, 4: 16}
上例中,dict3 的创建相当于如下代码的简写形式:
dict3 = {}
for x in range(5):
if x % 2 == 0:
dict3[x] = x ** 2
5.2 访问字典
不同于列表或元组,访问字典的元素不是通过偏移量,而是通过键来进行。
days = {1: 'Monday', 2: 'Tuesday', 3: 'Wednesday', 4: 'Thursday', 5: 'Friday', 6: 'Saturday', 7: 'Sunday'}
print(days) # {1: 'Monday', 2: 'Tuesday', 3: 'Wednesday', 4: 'Thursday', 5: 'Friday', 6: 'Saturday', 7: 'Sunday'}
print(type(days)) # <class 'dict'>
print(len(days)) # 7
print(list(days)) # [1, 2, 3, 4, 5, 6, 7]
print(days.get(3)) # Wednesday
print(days.get(8)) # None
if 3 in days:
print(days[3]) # Wednesday
5.3 修改字典
字典对象是可变的,可以随时修改其中的元素,或向其中添加新的键/值对,这些操作都可以通过 d[key] = value 的方式实现。另外,可以通过 del d[key] 删除字典中的某个元素。
days = {1: 'Monday', 2: 'Tuesday', 3: 'Wednesday', 4: 'Thursday', 5: 'Friday', 6: 'Saturday', 7: 'Sunday'}
if 7 in days:
del days[7] # 删除元素
days[0] = 'Sunday' # 添加新元素
print(days[0]) # Sunday
print(days[1]) # Monday
days[1] = '星期一' # 修改元素值
print(days[1]) # 星期一
5.4 字典视图对象
由 dict.keys(), dict.values() 和 dict.items() 所返回的对象是视图对象。该对象提供字典内项目的一个动态视图,这意味着当字典改变时,视图也会相应改变。字典视图可以被迭代以产生与其对应的数据,并支持使用 in 运算符进行成员检测。
days = {1: 'Monday', 2: 'Tuesday', 3: 'Wednesday', 4: 'Thursday', 5: 'Friday', 6: 'Saturday', 7: 'Sunday'}
print(days.keys()) # dict_keys([1, 2, 3, 4, 5, 6, 7])
print(days.values()) # dict_values(['Monday', 'Tuesday', 'Wednesday', 'Thursday', 'Friday', 'Saturday', 'Sunday'])
print(days.items()) # dict_items([(1, 'Monday'), (2, 'Tuesday'), (3, 'Wednesday'), (4, 'Thursday'), (5, 'Friday'), (6, 'Saturday'), (7, 'Sunday')])
# 可以通过 list(), tuple() 或 set() 函数将这些视图对象转换为列表、元组或集合
print(list(days.keys())) # [1, 2, 3, 4, 5, 6, 7]
print('Wednesday' in days.values()) # True
5.5 遍历字典
一般通过遍历某个字典视图对象来遍历字典。如下所示:
days = {1: 'Monday', 2: 'Tuesday', 3: 'Wednesday', 4: 'Thursday', 5: 'Friday', 6: 'Saturday', 7: 'Sunday'}
for key, value in days.items():
print(key, value)
# 1 Monday
# 2 Tuesday
# 3 Wednesday
# 4 Thursday
# 5 Friday
# 6 Saturday
# 7 Sunday
作业
- 写出两种以上用来创建内含 5 个整数零的列表的示例代码。
-
对于如下元组:
t = (3, 7, 8, 11)编写一个表达式,仅将其中的第一个元素
3修改为1,请给出两种方法。 -
自行从网络上搜索并学习冒泡排序法,实现在不使用 Python 中已有的用于排序的函数的前提下,对以下列表中的数字按照从小到大的顺序进行排序:
numbers = [43, 78, 31, 0, 63, 13, 23, 31, 20, 61]然后再自行学习二分查找法,不使用任何列表方法,也不使用
in运算符,用二分查找法快速找出排序后的列表中值43所对应的索引位置。
作业
-
某个班级期末考试的成绩单如下:
考试成绩单 学号 姓名 数学 英语 物理 2001 张三 88.5 64.0 75.0 2002 李四 78.0 65.5 90.0 2003 王老五 67.2 58.0 79.0 2004 白冰冰 87.0 92.5 89.0 2005 赵晓静 78.0 81.0 67.5 请编写一个程序,选择适当的数据结构用一个变量存储上表中所有信息,计算并在该变量中存储所有学生的平均成绩,以类似表格的形式打印该班级的成绩单,要求表格比上表至少多一列和一行,即在最后一列打印各学生的平均成绩,同时在最后一行适当位置打印各科的平均成绩,以及总平均成绩。
选做:同时打印各人的班级排名,并按平均成绩从高到低的顺序排列各行。
提示:使用 f-string 或转义字符(如
\t)以打印出样式美观的表格。
作业
-
将上一题所编制的程序改造为一个查询程序,程序提示输入学号进行成绩查询。当输入的学号存在时,打印该学生的成绩信息;当输入的学号不存在时,提示输入信息有误。该程序能无限循环执行下去,直到输入
exit时才退出。提示:为了能快速查找,可以使用字典存储班级成绩表,字典的键设为学号。
作业
要求:
- 将本章全部作业放在一个
安模作业02-04-学号-姓名.py的源文件中,通过电子邮件以附件形式发给任课教师。 - 在源文件中以注释的形式醒目地写明本次作业对应的章编号、各个作业题的编号,并按要求写出解题思路、代码注释。
- 以上各题不能只有文字说明,而应同时有可执行的示例代码。
- 邮件标题统一用
安模作业02-04-学号-姓名的形式。 - 所有关于作业的回答都以代码注释的形式写在源文件中,不需要再额外附加其他文档或图片,请保证代码执行不会发生错误。
- 待本次作业批改后,请通过此链接下载本次作业的参考答案。